
Der digitale Wandel hat Unternehmen dazu veranlasst, traditionelle papierbasierte Dokumentenabläufe durch effiziente und zeitsparende digitale Lösungen zu ersetzen. In diesem Zusammenhang hat sich die OCR-Texterkennung als essenzieller Bestandteil moderner Dokumentenmanagementsysteme etabliert. In diesem Blogartikel klären wir, was OCR bedeutet und werfen wir einen detaillierten Blick auf die Bedeutung der OCR-Texterkennung in der heutigen Geschäftswelt und welche Vorteile sie Unternehmen bietet.
Was ist OCR-Texterkennung?
OCR steht für „Optical Character Recognition“. OCR Texterkennung findet nicht nur im Dokumentenmanagement-System Anwendung, sondern begegnet uns auch im Alltag. Die PLZ von Briefen werden damit automatisch ausgelesen. Ebenso die Nummernschilder auf Radarbildern von Verkehrssündern.
Wie funktioniert OCR-Software?
Damit Informationen aus papierbasierten Dokumenten in IT-Systemen verarbeitet werden können, reicht es nicht, Dokumente einfach nur einzuscannen. Das digital vorliegende Dokument, wie der Scan oder das PDF, ist immer nur eine Bildkopie – die sogenannte Rastergrafik – eines Dokumentes. Nicht mehr und nicht weniger. Eine Ansammlung schwarzer, weißer oder farbiger Bildpunkte, die allerdings noch nicht „sprechen“ können. Das vermag die sogenannte optische Zeichenerkennung zu ändern. Mithilfe einer mehrschrittigen Analyse erkennt OCR-Software dann einzelne Buchstaben und setzt diese zu Wörtern und anschließend zu logischen Sätzen zusammen – das Bild wird in Text übersetzt. Auf diese Weise wandelt die klassische OCR-Technologie unterschiedliche Dokumente zuverlässig in bearbeitbare und durchsuchbare Dateien (wie Word- oder Exceldateien) um. Erst jetzt ist das elektronisch erstellte Dokument voll durchsuchbar, wenn nötig weiter bearbeitbar und für die automatisierte Datenextraktion nutzbar.
Mit der automatischen Dokumentenerkennung auf dem Weg in die Zukunft.
Welche Technologie ist die Richtige für deine Anforderungen?
Zonale OCR
Zonale OCR ist eine spezielle Art von Optical Character Recognition, die nur bestimmte Textdatenfelder aus einem Dokument extrahiert. Denn in einigen Anwendungsfällen, beispielsweise bei Formularen, ist es nicht notwendig, den gesamten Text eines Dokumentes zu erfassen. Formulare können dabei fast alles sein – von Auftragsformularen bis hin zu Patienteninformationen, Lagerbeständen oder Frachtbriefen. Aus diesen Dokumenten werden häufig nur spezifische Informationen benötigt, sodass nicht das gesamte Dokument beim Scannen verarbeitet werden muss. Zonale OCR erlaubt grundsätzlich, nur die wichtigen Datenfelder aus einem PDF-Dokument zu extrahieren und diese Werte in einer strukturierten Datenbank zu speichern. Die Extraktion basiert demzufolge auf „Zonen“, die vor dem Scannen definiert werden. Dies kann entweder durch Vorkonfigurierung durch Mitarbeiter:innen geschehen oder es werden intelligente Softwarekomponenten eingesetzt, die auf regelbasierten Erkennungsmöglichkeiten zurückgreifen. Ziel und Vorteil der zonalen OCR im Vergleich zur Volltext-OCR ist es, bestimmte Daten noch schneller und mit einer höheren Genauigkeit erfassen zu können.
Plant ein Unternehmen etwa ein DMS einzuführen und möchten Altdaten, wie Rechnungen, archivieren und diese dann einer entsprechenden Kreditorenakte zuordnen, ist es ausreichend, an dieser Stelle lediglich die Rechnungsnummer über zonale OCR auszulesen. Andere Positionsdaten können vorerst außer Acht gelassen werden. Das macht die zeitintensive Volltexterkennung überflüssig.
ICR (Intelligent Character Recognition)
Wer einen handgeschriebenen Brief einscannt und dann eine optische Texterkennung startet, erlebt sein blaues Wunder. OCR deckt nur den Bereich der Verarbeitung von gedruckten Schriftstücken in zufriedenstellender Weise ab. Der Prozess der Erkennung handschriftlicher Einträge ist allerdings technisch sehr viel anspruchsvoller. Daher wird hier die Intelligent Character Recognition – auch ICR – als eine Erweiterung der optischen Zeichenerkennung genutzt. Das funktioniert in den meisten Fällen am besten per Blockschrift und wenn die Blockschrift Begrenzungen aufweist. Bestes Beispiel ist hier der gute alte Überweisungsschein.
OMR (Optical Marc Recognition)
Mit der optischen Markierungserkennung können optische Markierungen in Formularen und Fragebögen besser als mit OCR oder ICR ausgelesen werden. Die Technik wird deswegen häufig zur automatischen Auswertung von Ankreuzfeldern in Formularen, wie bei Multiple-Choice-Tests, Wahlzetteln oder Datenprüfungen verwendet. Die OMR-Software wertet die markierten Formulare aus, wobei sie zwischen markierten und unmarkierten Feldern unterscheidet. Zu beachten ist hier, dass die Technik sehr sensibel auf den Zustand des Papiers reagiert.
Dokumentenmanagementsysteme kommen folglich nicht ohne OCR-Texterkennung aus. Dabei ist es ganz egal, welche Anforderungen du mitbringst. Stelle bei der Auswahl eines geeigneten Systems immer sicher, dass optische sowie intelligente Erkennungstechnologien als Softwarekomponenten clever implementiert sind. Denn das macht die digitalen Dokumentenprozesse noch schneller und leistungsfähiger.

Verschiedene Einsatzgebiete von OCR-Technologie im Alltag
Im Alltag findet die OCR-Technologie vermehrt Anwendung. Die meisten haben OCR auch schon genutzt, ohne zu wissen, um welche Technologie es sich handelt. Jeder, der schon mal im Internet geshoppt hat oder eine Reise im Internet gebucht hat, ist der OCR-Technologie bereits begegnet. Geht es nämlich um das Bezahlen, musste man mühsam die Daten der Kreditkarte abtippen, um den Kaufvorgang abzuschließen – nicht mehr, seit die OCR-Technologie zum Einsatz kommt. Mithilfe der Kamera des Smartphones können die Daten der Kreditkarte eingelesen und das Bezahlformular automatisch ausgefüllt werden. So erleichtert die Erkennung der OCR vielen Online-Shoppern den Alltag.
Ein weiteres Beispiel aus dem Alltag, was sicher viele kennen, ist die Verwendung einer Übersetzter-App. Aktiviert man hierbei die Foto-Übersetzung, muss man lediglich die Kamera vor den Text halten, der übersetzt werden soll und schon hat man den Text in der gewünschten Sprache. Hier ist auch die OCR-Technologie im Spiel. Die Kamera nimmt den Text auf und mit einer mehrstufigen Analyse wird das Bild entschlüsselt und eingelesen. Diese eingelesenen Daten übersetzt die Übersetzter-App in Echtzeit.
Wusstest du, dass sogar dein Auto OCR-Technologie verwenden kann? In einigen Autos gibt es die Funktion der Verkehrszeichenerkennung. Auch hier kann die OCR-Technologie verwendet werden. In einer Offenlegungsschrift des Deutschen Patent- und Markenamtes zum Thema Erkennung von Verkehrszeichen heißt es: „Die Erkennung des Verkehrszeichens unter Berücksichtigung des geschärften Bildbereichs kann über eine Mustererkennung, Klassifikation bzw. eine Texterkennung (OCR) erfolgen.“
Verschiedene Einsatzgebiete von OCR-Software im Dokumentenmanagement
Die OCR-Technologie wird in verschiedenen Bereichen eingesetzt. In vielen Fällen kommt die OCR-Technologie bei der Erfassung von Dokumenten zum Einsatz. Das Ziel, das dabei verfolgt, wird ist, dass Papierdokumente auf schnelle und einfache Art, digital verfügbar gemacht werden. So können verschiedene Mitarbeiter:innen von überall auf die Dokumente zugreifen – und das dank OCR.
OCR-Texterkennung als Herzstück des Dokumentenmanagement-Systems
Die Fähigkeit der OCR, eine Textversion von gescannten Dokumenten zu erstellen, ermöglicht es den Mitarbeiter:innen eine Volltextsuche durchzuführen und somit jeden Teil eines Dokumentes mit einer bestimmten Menge von Wörtern aufzufinden. Dokumente können auf diese Weise schnell und einfach im Archiv oder in der Cloud aufgerufen und dort mit einem Textverarbeitungsprogramm bearbeitet werden. Der Volltext der OCR ist auch für eine Klassifizierung von Dokumenten notwendig. Klassifizierung von unstrukturierten Dokumenten gelingt, indem die Software einzelne Kategorien, bestimmte Daten und Eigenschaften (Attribute) eines Dokumentes erkennt und anhand dieser Merkmale die Dokumentenart treffsicher und automatisch bestimmt. Wichtig sind diese Schritte beim Szenario des Posteingangs. Bei der Eingangsrechnung kann ein Prozess wie folgt aussehen:
- Eingehende Rechnungen werden eingescannt
- Kopf- und Positionsdaten werden dank OCR automatisch erkannt (und gegebenenfalls gegen Bestell- und Bewegdaten abgeglichen)
- Das Dokument sowie die erkannten Daten (Absender, Empfänger, Rechnungsnummer, Beträge) werden bereitgestellt.
OCR schafft hier die Grundlage für eine vereinfachte und automatisierte Erschließung und Verteilung von Dokumenten mithilfe des Dokumentenmanagementsystems. Letztlich sorgt die OCR-Software dafür, dass eine beschleunigte Sortierung, Zuordnung und Verarbeitung des täglichen Schriftverkehrs im Unternehmen stattfinden kann.
Je nach Anforderung kommen die unterschiedlichen Techniken der Erkennung zum Einsatz.
Der digitale Posteingang mittels OCR-Texterkennung
Betrachtet man etwa den Ablauf des Posteingangs kann auch hier OCR eingesetzt werden, um den Ablauf zu optimieren. Ein physisches Poststück kommt bei einem Unternehmen an und liegt beispielsweise am Empfang. Dort liegt es dann einige Zeit, bis es geöffnet und bearbeitet wird. Es muss geschaut werden, ob das Poststück geöffnet werden darf, wer der/die Empfänger:in ist, um welche Art Poststück es sich handelt und relevante Informationen müssen händisch erfasst und vom Dokument abgetippt werden. Das dauert oftmals lange und bindet viele personelle Ressourcen.
Einfacher wäre es doch, den Brief zu scannen und den/die Empfänger:in direkt per Mail zu benachrichtigen, dass ein neues Poststück für ihn/sie bereitliegt. Den Rest übernimmt die Software.
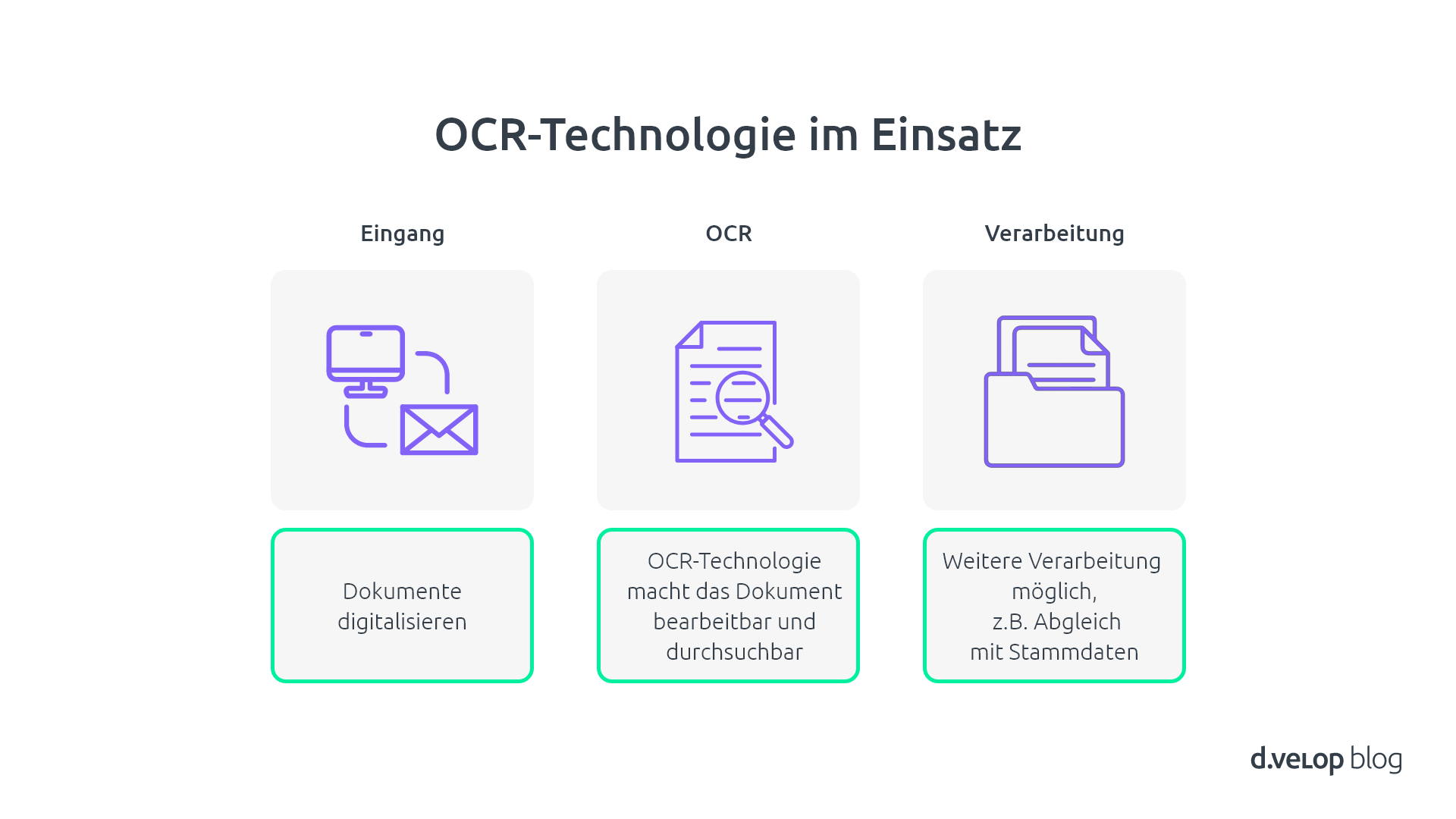
Denn mithilfe der OCR-Technologie ist der Grundstein für eine voll automatische Klassifizierung und Verarbeitung von jeglichen eingehenden Dokumenten gelegt. Auf Basis der vom Papierdokument ausgelesen Daten kann die d.velop Software anhand von Regeln und Mustern automatisch klassifizieren, um welche Art von Dokument es sich handelt und alle relevanten Informationen wie Empfänger:in, Absender:in, Beträge oder eine Umsatzsteuer-ID extrahieren. Das zeitaufwendige manuelle Abtippen von Informationen und das händische Übertragen dieser in eine Folge Software entfallen damit komplett. Darauf aufbauend können entsprechend weiterführende Aufgaben im Rahmen des Dokumentenmanagements angestoßen werden.
Weitere Einsatzgebiete für die OCR-Technologie können folgende sein:
- Digitalisierung eingescannter Briefe und Rechnungen
- Eingescannte Dokumente mittels computergestützte Systeme leicht durchsuchbar machen
- Archivierung von Dokumenten und Akten
- Vorbereitung für Verarbeitung durch andere Software
- Eingescannte oder abfotografierte Texte bearbeiten
Mit der richtigen Software kann der gesamte Posteingang einfach und schnell digital erfasst werden. Im Webinar erfährst du, wie. ▶ Webinar ansehen!