
Wenn man nicht gerade aus der IT-Welt stammt, können bereits gängige Begriffe ziemlich verwirrend sein. So macht das Thema Metadaten, gerade im Bereich von Microsoft SharePoint, einigen Anwendern zu schaffen.
Zu Beginn ist die Frage zu klären, was Metadaten überhaupt sind. Einfach gesagt: Es sind Daten über Daten. Natürlich kann man Dokumenten, Videos, Bildern etc. einen sinnvollen Namen verpassen. Allerdings gibt es oft genug zu viele verschiedene Informationen, nach denen man suchen oder filtern möchte. Das tritt besonders bei großen Datenmengen auf. Und da ergibt es keinen Sinn, den abgelegten Daten einen endlosen Namen zu geben. An dieser Stelle kommen die Metadaten ins Spiel und sind in den Dokumenteneigenschaften zu finden. Pflegt man diese strukturiert und sorgfältig, macht es das Finden kinderleicht und lange Recherchen bleiben erspart.
Beispiele für Metadaten sind:
- Name
- Verantwortlicher
- Rechnungsnummer
- Kostenträger
- Artikelnummer
- Kunde
- Kündigungsfrist
Wie sortiert man eine Bibliothek mit Hilfe von Metadaten in SharePoint?
Im Standard sind bereits einige Metadaten-Elemente vorhanden, mit denen gearbeitet werden kann, wie beispielsweise das Änderungsdatum oder der Dateityp. Allerdings wird die Arbeit mit Metadaten erst dann richtig effektiv, wenn man auf seine Aktivitäten und Dokumente abgestimmte Informationen pflegt und verwaltet.
Doch wie erstellt man überhaupt neue Metadatenelemente?
Wichtig ist zuallererst, dass man die Berechtigung besitzt, um diese Änderungen vorzunehmen. Ist das geklärt, steht der Optimierung nichts mehr im Wege.
Hovert man über die Kopfzeile in der Dokumentenübersicht, erscheint zwischen den Spalten ein Plus. Nach dem Klick öffnet sich ein Menü in welchem man vorhandene Spalten auswählen oder über „Mehr…“ neue Spalten erstellen kann, sofern man eine komplett neue „Datenkategorie“ einrichten möchte. Per Drag and Drop lässt sich die Anordnung der Spalten verändern. Über den Punkt „Spalten ein-/ausblenden“ kann die Ansicht ebenfalls verändert werden. Es gibt noch viele weitere Wege und Möglichkeiten, diese Einstellungen vorzunehmen, allerdings ist diese die einfachste und gängigste.
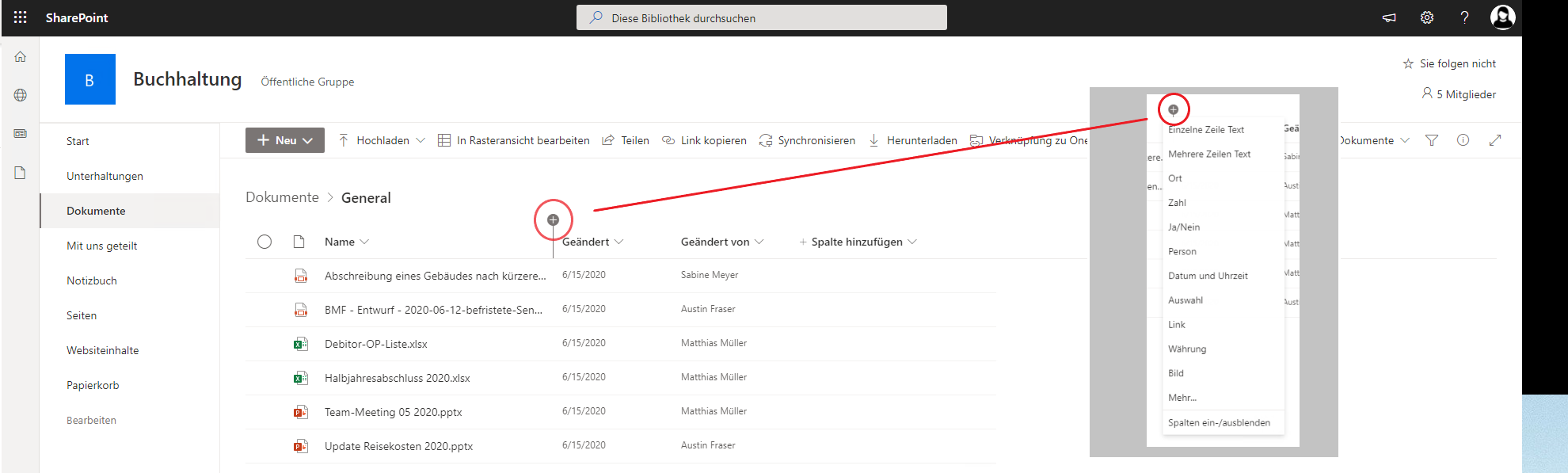
Um in verschiedenen Dokumentenbibliotheken nicht immer jede Sortierung neu vornehmen zu müssen, kann man die Ansicht der Spalten speichern. Dies geschieht über die Funktion „Inhaltstyp“ im selben Menü, welches über das Plus zwischen den Spalten aufgerufen werden kann.
Good2Know: Verändert sich die Ansicht in der Dokumentenbibliothek in SharePoint, so ändert sich die Ansicht im zugewiesenen Teamsordner ebenfalls mit.
SharePoint Metadaten: 3 wichtige Regeln
Nutzt man SharePoint als standardisierten Dokumentenspeicherort, arbeitet man nicht wie üblich im Explorer mit Ordnern, sondern mit Listen und Bibliotheken. Aus diesem Grund spielen Metadaten im SharePoint eine noch wichtigere Rolle, um das Gesuchte schnell zu finden. Damit jede:r Benutzer:in weiß, nach welchen Eigenschaften gesucht werden kann, gilt es 3 wichtige Regeln zu beachten.
(1) Sinnvolle Struktur erstellen
Überlegt euch gemeinsam mit dem Team vorab, welche Themen Euch in der täglichen Arbeit beschäftigen, mit welchen Dokumenten Ihr arbeitet und welche Informationen schnell gefunden werden müssen. Versucht anschließend Zusammenhänge zu bilden und Regeln festzulegen, wo welche Dokumententypen abgelegt werden sollen. Wenn jeder in seiner eigenen Ablagestruktur verbleibt, kann Microsoft SharePoint noch so gute Recherche-Möglichkeiten bieten; Wenn keine Grundordnung herrscht, kann die Suche nicht auffällig vereinfacht werden.
(2) Keine doppelten Metadaten-Elemente
Zu dieser strategischen Überlegung gehört auch die Festlegung relevanter Metainformationen, die gepflegt werden sollen und dürfen. Erstellen zwei oder mehrere Personen unabhängig voneinander ein Element mit „Rechnungsnummer“ und „Rechnungsnr.“, so besitzen beide zwar dieselbe Information und werden regelmäßig gepflegt, jedoch sind diese nicht miteinander verknüpft. Sucht ein Außenstehender dann nach einer Rechnung, muss er sowohl „Rechnungsnummer“ als auch „Rechnungsnr.“ in seinen Filtereigenschaften berücksichtigen. Doch dazu muss er erst einmal wissen, dass beide Versionen existieren. Daher: Erstellt gemeinsam eine Metadaten-Elementübersicht ohne Informationsüberschneidungen!
(3) Regelmäßiges Pflegen der Metainformationen
Die Übersicht allein ist erst dann sinnvoll, wenn die Metadaten regelmäßig gepflegt werden. Stellt Pflichtfelder ein, bei Informationen die essenziell sind für die tägliche Recherche, um das Leerbleiben dieser Felder zu vermeiden. Doch angenommen, man legt einen Dokumentenstapel von 40 Dateien ab, so kann das Ausfüllen sehr viel Zeit in Anspruch nehmen. Im SharePoint Standard ist das automatische Auslesen von wichtigen Informationen leider noch nicht möglich und stößt an dieser Stelle an seine Grenzen.
Vor- und Nachteile von Metadaten im SharePoint
Für einen kleinen Überblick haben wir Dir die Vor- und Nachteile von SharePoint Metadaten zusammengefasst:
Vorteile:
- Alle relevanten Informationen auf einen Blick
- Intelligente Filteroptionen begünstigen kurze Recherchezeiten
- Daten werden strukturiert abgelegt & mit Hilfe der vorher zu definierenden Struktur auch langfristig so abgelegt – es existiert kein Datenwust
Nachteile:
- Bei manueller Metadatenpflege herrscht bei Ablage ein hoher Aufwand
- Die Komplexität könnte zunehmen, wenn auf Dauer zu viele Metadatenelemente und Spalten hinzugefügt werden
- Die Metadatenfilterung gilt pro Bibliothek. Existierten umfangreiche Ablagestrukturen über mehrere Bibliotheken, so muss an mehreren Stellen gesucht werden.
- Automatische Übernahme von Dokumenten und Metadaten aus führenden Office-/CRM-/ERP-Anwendungen ist nicht möglich.
Möglichkeiten zur automatischen Vergabe von SharePoint Metadaten
Wir sehen also, dass die Vergabe von Metadaten bereits im SharePoint Standard viele Vorteile mit sich bringt. In der gelebten Praxis jedoch fällt schnell auf: Der Aufwand der manuellen Vergabe von Metadaten übersteigt schnell den eigentlichen Nutzen. SharePoint bietet durch die Erweiterung Syntex bereits eine Lösung für dieses Problem an. Allerdings ist diese Funktion sehr umfangreich und aufwändig einzurichten und nicht wirklich intuitiv – Du siehst, wir landen auch hier beim gleichen Problem: Der nun automatisierte Aufwand der Vergabe von Metadaten übersteigt ebenfalls oft den Nutzen.
Mit dem SharePoint Dokumentenmanagement bietet d.velop an dieser Stelle einen echten Mehrwert. Verschiedenste Dokumentarten wie, z.B. Verträge oder Rechnungen, werden im Hintergrund automatisch ausgelesen und durch die Vergabe von Metadaten klassifiziert und in die richtigen Prozesse oder Aktenstrukturen überführt. So ergeben sich je nach Dokumentenart unterschiedliche Anwendungsfälle für die Software von d.velop.
Dokumentenmanagement
Auf Grundlage der zuvor beschriebenen Klassifizierung werden Dokumente automatisch in eine bestimmte Aktenstruktur überführt. Wie diese Aktenstruktur aussieht, ist sehr individuell – und reicht von Kunden- und Lieferantenakten bis hin zu Projekt- und Personalakten.

Eingangsrechnungsverarbeitung
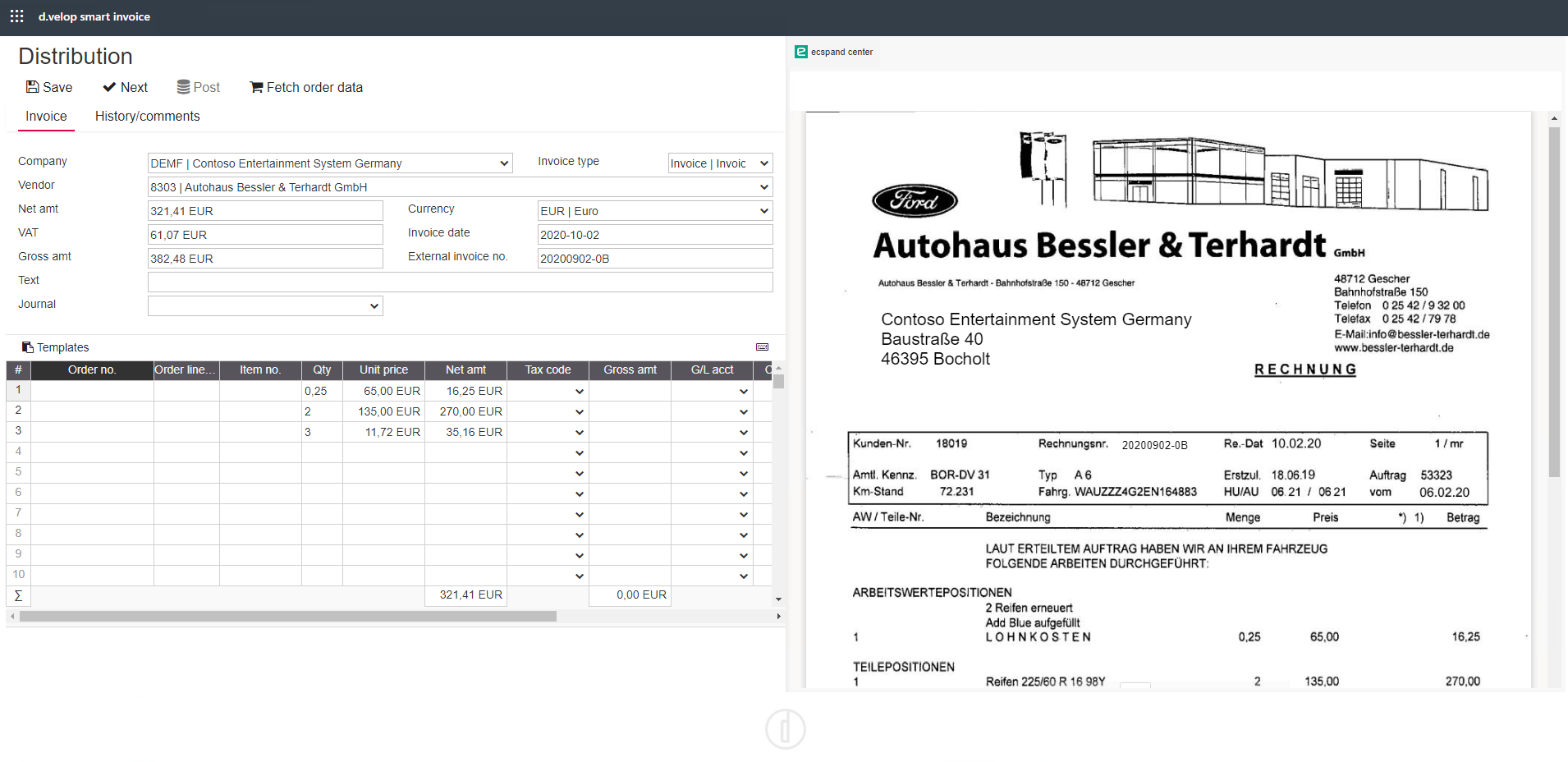
Metadaten ermöglichen erst den Start eines digitalen Workflows zur Rechnungsverarbeitung. Sowohl auf Kopf- als auch auf Positionsebene können diese ausgelesen werden und unterstützen den Anwender:innen in der sachlichen Prüfung und Freigabe der jeweiligen Rechnung.
Vertragsmanagement
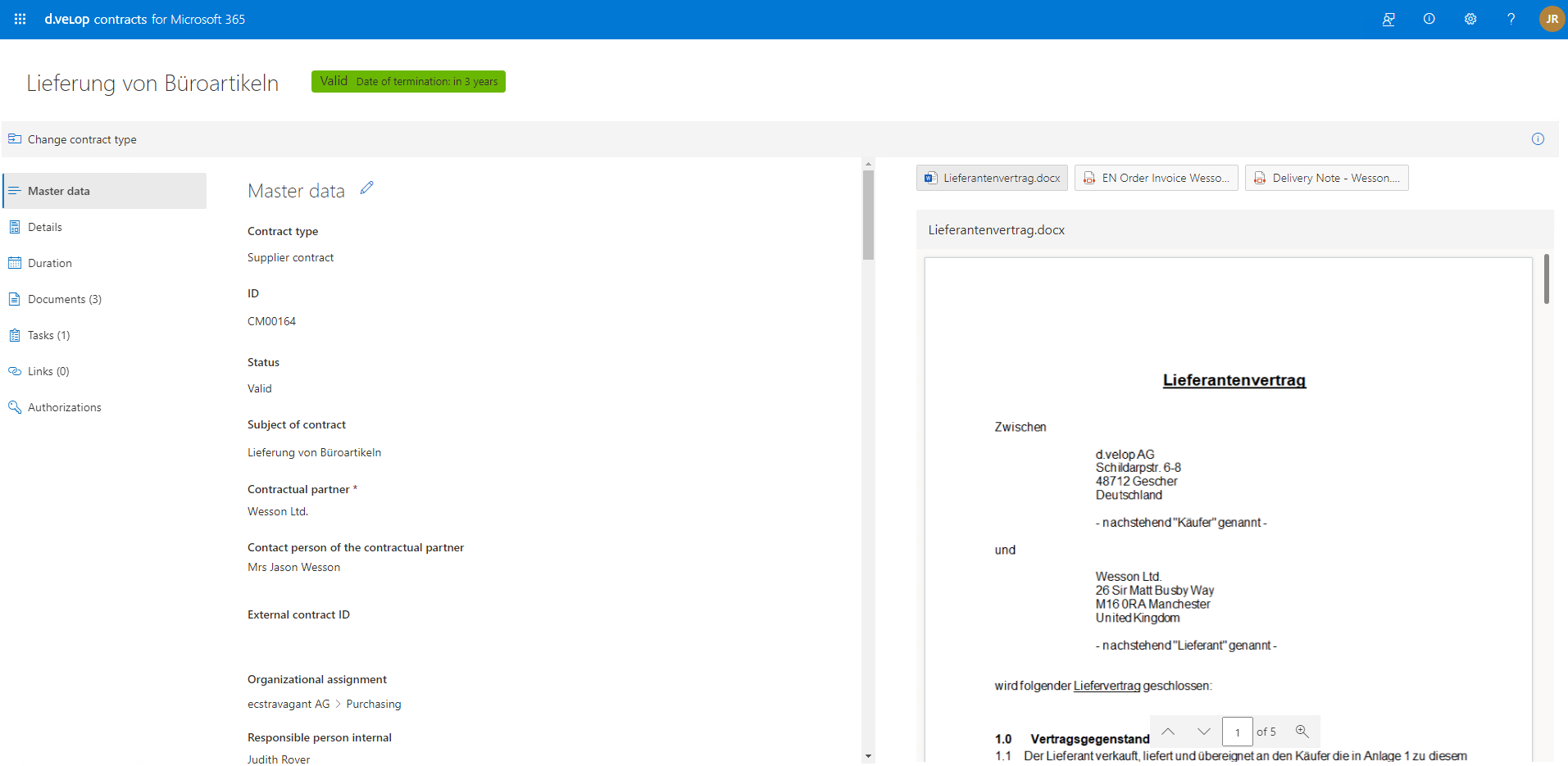
Wird ein Dokument als Vertrag klassifiziert und mit d.velop contracts for M365 verarbeitet, so kann dieses Dokument in einen vollständigen Lebenszyklus überführt werden. Zusammen mit anderen Dokumenten, wie z.B. einer Geheimhaltungsvereinbarung, sowie Fristen und Aufgaben kann eine umfassende Vertragsakte geschaffen werden.
Vollständiger Nutzen von Metadaten im Dokumentenmanagement
Jetzt erst wird der volle Nutzenumfang von Metadaten im Dokumentenmanagement deutlich. Automatisierte Klassifizierungs- und Verteilprozesse sparen nicht nur dem:der Anwender:in Zeit und Nerven, sondern sorgen in der gesamten Unternehmung für schlankere und effizientere Prozesse. Metadaten bilden ebenfalls die Grundlage für alle weiteren Prozesse, die das jeweilige Dokument betreffen: Erinnerungen, Prüfungen, Freigaben und viele weitere Funktionen werden so erst ermöglicht und garantieren, dass Du zu jeder Zeit die volle Transparenz und Sicherheit über Ihre Dokumente und Prozesse hast.
Mehr zum Thema Dokumentenmanagement, Eingangsrechnungsverarbeitung und Vertragsmanagement mit d.velop for Microsoft 365 erfährst du in unserer d.velop M365 Summer School – melde dich hier gerne direkt dazu an. Wir freuen uns auf Dich!