
Der Markt für Intelligent Document Processing wird reifer. Die Frage ist längst nicht mehr, ob KI Dokumente lesen kann – sondern was im Anschluss mit dieser Information passiert. Genau hier verschiebt sich gerade der Schwerpunkt: weg von der reinen Erkennung, hin zu einer Schicht, die Prozesse versteht, einordnet und vorbereitet. Aus Dokumentenanalyse wird Prozessintelligenz.
Was früher vor allem dazu diente, Dokumente zu klassifizieren, Daten auszulesen und an ein Folgesystem zu übergeben, rückt damit deutlich näher an die eigentliche Wertschöpfung heran. Für Unternehmen, die ihre Dokumentenprozesse, Workflows und DMS-Strukturen weiterentwickeln wollen, ist das eine wesentliche Veränderung. Denn der Nutzen entsteht heute nicht mehr allein aus der Frage, ob ein System ein Dokument korrekt erkennt. Relevant ist, was sich auf dieser Basis automatisieren, beschleunigen und qualitativ absichern lässt.
Der IDP-Markt wächst – und mit ihm die Erwartungen
Die größte Nachfrage nach IDP-Lösungen kommt nach wie vor aus dokumentenintensiven Branchen wie Versicherungen und Banken. Dort entstehen im täglichen Austausch mit Kunden besonders viele hochvolumige Prozesse – etwa in der Schadensbearbeitung, im Kreditantragsprozess oder im Änderungsmanagement. Aber auch im Gesundheitswesen helfen die automatisierte Erfassung, Klassifizierung und Verarbeitung von Daten, manuelle Aufwände deutlich zu reduzieren.
Längst ist IDP aber nicht mehr auf diese klassischen Felder beschränkt. Auch in der Luftfahrt und der Logistik wächst der Bedarf spürbar. Und ein weiteres Feld öffnet sich gerade: Kommunen, Stadtwerke und Behörden sind heute deutlich offener für Cloud-basierte Lösungen als noch vor wenigen Jahren – und stehen parallel unter erheblichem Druck, ihre dokumentenbasierten Prozesse zu modernisieren.
Wer heute erlebt, wie schnell moderne KI Inhalte aus Unterlagen erfassen, strukturieren und einordnen kann, stellt bestehende manuelle Abläufe zwangsläufig infrage. Diese neue Zugänglichkeit senkt die Einstiegshürden – Proofs of Concept werden heute deutlich schneller angestoßen als noch vor wenigen Jahren.
Mit der Offenheit steigen allerdings auch die Erwartungen. Viele Unternehmen kommen mit der Vorstellung auf das Thema zu, KI könne Dokumente ohne nennenswerten Aufwand übernehmen, verstehen und vollständig automatisiert verarbeiten. Genau an diesem Punkt beginnt in der Praxis die eigentliche Arbeit. Denn zwischen einem beeindruckenden Test und einem belastbaren Produktivsystem liegt ein erheblicher Unterschied.
Vom Lesesystem zum handelnden System
Die Entwicklung von IDP lässt sich in einem Satz zusammenfassen: Die Wertschöpfungskette endet nicht mehr beim sauber ausgelesenen Dokument.
Klassische IDP-Systeme hatten eine klar umrissene Aufgabe. Ein Dokument wurde erkannt, klassifiziert, extrahiert und an Mitarbeitende oder ein Folgesystem übergeben. Die eigentliche Entscheidung fand außerhalb des Systems statt. Diese Trennlinie verschiebt sich gerade. Moderne Plattformen verbinden Dokumentenanalyse zunehmend mit Workflow-Funktionen, Regelwerken, Stammdaten und Kontextwissen. Daraus entsteht ein neuer Systemcharakter: Aus einem Analysesystem wird schrittweise ein prozessnahes, teilweise sogar handelndes System.
Das Ziel ist, Mitarbeitenden fallabschließende Entscheidungen zu ermöglichen –
René Weseler,
nicht nur Dokumente auszulesen.
Senior Executive Manager bei Buildsimple
Das System soll nicht nur sagen, was in einem Dokument steht, sondern idealerweise auch, was als Nächstes passieren sollte. Wie weit Unternehmen diesen Schritt gehen wollen, ist offen – gerade in sensiblen Kernprozessen. Die Richtung aber ist klar: IDP wird von einer vorgelagerten Erkennungstechnologie zu einer intelligenten Prozesskomponente.
Wie man LLMs sinnvoll für Dokumente einsetzt
Sobald über KI in Dokumentenprozessen gesprochen wird, landet die Diskussion fast automatisch bei Large Language Models. Das ist nachvollziehbar: Diese Modelle haben die Wahrnehmung des Themas stark verändert. Sie sind leistungsfähig, leicht zugänglich und in vielen Szenarien beeindruckend. Deshalb sind sie ein wichtiger Baustein, aber nicht automatisch die beste Lösung für jeden Anwendungsfall.
LLMs sind generative Systeme. Sie lesen Informationen nicht einfach aus, sie erzeugen Antworten. Darin liegt ihre Stärke. In hochvolumigen, regulierten Prozessen, in denen Ergebnisse reproduzierbar, erklärbar und auditierbar sein müssen, braucht es auch andere Eigenschaften.
Wer hohe Dunkelverarbeitungsquoten in einem Kernprozess erreichen will, braucht vor allem Stabilität. Deshalb bleiben selbst trainierte Machine-Learning-Modelle in vielen Anwendungsfällen die bessere Wahl. Sie lassen sich auf konkrete Dokumententypen trainieren, liefern bei identischem Input identische Ergebnisse und schaffen ein Maß an Nachvollziehbarkeit, das gerade in regulierten Umgebungen zählt.
Das heißt nicht, dass LLMs keine Rolle spielen. Im Gegenteil: Sie entfalten ihre Stärken dort, wo Sprachverständnis, Einordnung, Bewertung oder Zusammenfassung gefragt sind. In der Praxis zeigt sich deshalb zunehmend ein differenzierter Ansatz. Selbst trainierte Modelle übernehmen die robuste, reproduzierbare Extraktion. LLMs ergänzen dort, wo zusätzliche semantische Tiefe gefragt ist oder wo Ergebnisse ohnehin von einem Menschen geprüft werden. Der Markt wird hier sichtbar reifer: Unternehmen fragen nicht mehr nur nach KI, sondern sehr konkret danach, welche Technologie für welchen Use Case sinnvoll ist. Ein Multi-KI-Ansatz sorgt bei Buildsimple beispielsweise dafür, dass für jede Aufgabe das passende Verfahren zum Einsatz kommt – für stabile, wirtschaftliche und nachvollziehbare Ergebnisse.
Qualität entscheidet sich nicht im Pilotprojekt, sondern im Betrieb
Ein weiteres Missverständnis ist die Annahme, ein erfolgreicher Pilot sei bereits der Beweis für einen funktionierenden Produktivbetrieb. In Wahrheit beginnt die eigentliche Herausforderung oft erst danach.
Früher konzentrierte sich Qualitätssicherung vor allem auf klassische OCR-Fehler. Heute geht es stärker um Vertrauen in die KI selbst. Kann das System seine Ergebnisse stabil reproduzieren? Lassen sie sich erklären? Und wie wird verhindert, dass fehlerhafte Ergebnisse unbemerkt durch einen Prozess laufen?
Ein bewährter Weg ist die Arbeit mit Konfidenzwerten. Systeme liefern für Klassifikation und Extraktion Wahrscheinlichkeiten mit, die im produktiven Einsatz über einen definierten Zeitraum kalibriert werden. Zu Beginn prüfen Menschen die Ergebnisse engmaschig nach – vollständig oder anhand eines repräsentativen Sets. Auf dieser Basis lassen sich Schwellenwerte definieren, ab denen Fälle sicher automatisiert verarbeitet werden können. Alles darunter bleibt bei den Sachbearbeitenden.
Dieses Zusammenspiel aus Automatisierung und kontrollierter menschlicher Prüfung ist in vielen Projekten der entscheidende Erfolgsfaktor. Im B2B-Umfeld geht es nicht um spektakuläre Demos, sondern um belastbare Prozesse unter realen Bedingungen.
Praxisbeispiel: DMB Rechtsschutz zeigt, wie IDP heute funktioniert
Wie diese Entwicklung konkret aussehen kann, zeigt das gemeinsame Projekt von d.velop und Buildsimple bei der DMB Rechtsschutz-Versicherung AG. Buildsimple ist eine Plattform für dokumentenbasiertes Inputmanagement, die KI-gestützte Dokumentenerkennung mit nahtloser Integration in bestehende DMS- und Workflow-Systeme verbindet.
Die DMB Rechtsschutz betreut mit 63 Mitarbeitenden über 140.000 Versicherungsverträge und verarbeitet jährlich rund 160.000 eingehende Dokumente über drei Eingangskanäle. Schon vor dem Projekt nutzte das Unternehmen d.velop documents für die digitale Archivierung und Workflow-Steuerung. Die Herausforderung lag im vorgelagerten Dokumenteneingang: Viele Unterlagen mussten manuell gesichtet und den zuständigen Fachbereichen zugeordnet werden. Das kostete Zeit, band Kapazitäten und erhöhte die Fehleranfälligkeit.
Die Ausgangslage war typisch für viele Versicherer. Eingehende Briefe wurden zunächst von einem Scan-Dienstleister digitalisiert und vorinitialisiert. Konnten dabei Vertrags- oder Schadennummern erkannt werden, war eine maschinelle Zuordnung möglich. Fehlten solche Informationen oder handelte es sich um Faxe und E-Mails, musste die interne Posteingangsstelle die Dokumente sichten und manuell weiterleiten.
Gesucht war deshalb keine isolierte KI-Lösung, sondern eine intelligente Ergänzung für einen bereits bestehenden dokumentenbasierten Prozess – und zwar so, dass sie sich nahtlos in die vorhandene d.velop-Infrastruktur integrierte. Innerhalb von acht Monaten setzte Buildsimple gemeinsam mit d.velop und DMB Rechtsschutz eine produktive Lösung um, die heute mehr als 70 Dokumentenklassen sicher erkennt und relevante Fachdaten wie Vertrags-, Schaden- und Vermittlernummern extrahiert. Sowohl bei der Dokumentenklassifikation als auch bei der Erkennung der Fachdaten werden Trefferquoten von über 90 Prozent erreicht.
Im Januar 2025 haben wir mit der Implementierung begonnen und konnten das Projekt innerhalb von acht Monaten umsetzen. Da können wir in der Zusammenarbeit zwischen d.velop, Buildsimple und DMB Rechtsschutz mächtig stolz drauf sein.
Mario Dederichs,
IT-Leiter DMB Rechtsschutz-Versicherung AG
Vom KI-Modell zur integrierten Prozesslösung
Interessant ist auch der technologische Ansatz. Buildsimple setzt auf ein Foundation Model: Statt KI-Modelle für jeden Anwendungsfall von Grund auf zu trainieren, baut die Plattform auf einem vortrainierten Sprach- und Strukturverständnis auf. So lassen sich individuelle Modelle mit deutlich weniger Trainingsmaterial entwickeln: Im DMB-Rechtsschutz-Projekt genügten rund 100 Beispiele pro Dokumentenklasse statt mehrerer tausend, die klassische Verfahren typischerweise benötigen.
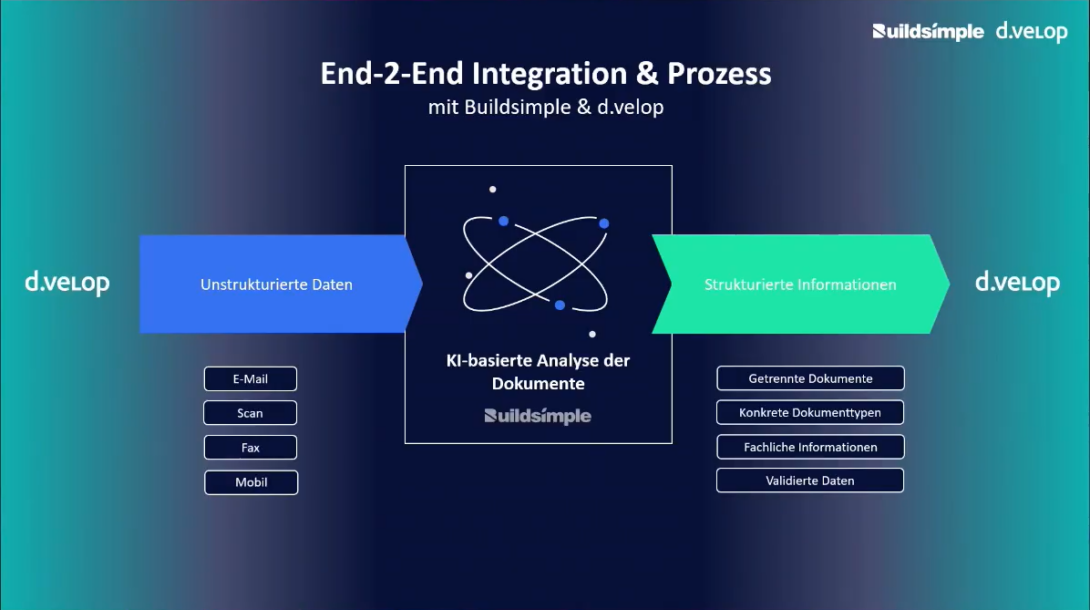
Der eigentliche Hebel liegt jedoch nicht in der Erkennung, sondern in der Integration. Buildsimple band seine Lösung vollständig in das bestehende d.velop-System ein. So entstand ein End-to-End-Prozess von der Dokumentenerkennung über die Datenextraktion bis zur Übergabe in die Workflows. Genau daran zeigt sich, wohin sich IDP entwickelt: nicht zu einem losgelösten Spezialwerkzeug, sondern zu einer intelligenten Prozesskomponente innerhalb einer gewachsenen Systemlandschaft. Für die DMB Rechtsschutz bedeutet das weniger manuellen Aufwand im Posteingang, schnellere Zuordnung, höhere Prozessqualität und mehr Zeit für die fachlich anspruchsvollen Fälle.
Praxisbeispiel im Video anschauen
Was Unternehmen daraus ableiten sollten
Erstens: IDP sollte nicht mehr als isolierte Eingangstechnologie gedacht werden. Der größte Hebel entsteht dort, wo Dokumentenerkennung mit DMS, Workflow und Prozesslogik zusammengeführt wird.
Zweitens: Wer reproduzierbare und auditierbare Ergebnisse braucht, sollte die Architektur am konkreten Use Case ausrichten.
Drittens: IDP wächst tiefer in die Prozesse hinein. Dokumente werden nicht mehr nur erkannt und ausgelesen, sondern zum Ausgangspunkt für strukturierte Entscheidungen, priorisierte Bearbeitung und perspektivisch weitergehende Automatisierung. Wer IDP heute noch als reine Erkennungstechnologie versteht, greift zu kurz. Genau deshalb sprechen wir nicht mehr nur über Dokumentenanalyse, sondern auch über Prozessintelligenz.
💻 Software Demo buchen
Fordern Sie mit wenigen Klicks Ihre individuelle Live-Demo zur Software von d.velop an. Lassen Sie sich die Software live vorführen und stellen Sie direkt Ihre Fragen.
Einfach Button anklicken, Formular ausfüllen und wir melden uns bei Ihnen.