
Unter diesem Titel fand auf dem d.velop SUMMIT 2025 eine besonders begehrte Masterclass statt. Unsere beiden Senior Software Development Engineers, Jan Föcking und Lars Feßen-Fallsehr, demonstrierten im Tech Lab eindrucksvoll, wie aus einem Large Language Model (LLM) ein echter, intelligenter und autonomer KI-Assistent wird. Schritt für Schritt, nicht nur in der Theorie, sondern auch mit Live-Coding, praxisnahen Beispielen, einem durchgängigen Use Case aus dem Messe-Alltag und jeder Menge Aha-Momente.
In einer Zeit, in der Begriffe wie „künstliche Intelligenz“ und „Agenten“ oft nur als Schlagworte des Digitalisierungstrends umher geistern, wollten die KI-Experten von d.velop zeigen, was wirklich dahintersteckt. „Hier geht es nicht nur um KI als Buzzword, sondern echtes KI-Agenten-Know-how“, betonte Moderator Fabien Davids.
Erlebe den Vortrag (noch einmal) – in dem die beiden erläuterten, wie LLMs gezielt eingesetzt werden können, um Nutzer:innen mit hilfreichen Informationen zu versorgen, wie sich die technische Entwicklung der letzten Jahre vollzogen hat und wie sich aus einem großen Sprachmodell ein agentenbasiertes System entwickeln lässt – mit RAG, Knowledge Graphs und einer Prise „heißem Scheiß“, wie Jan Föcking sagen würde.
Was ist das Tech Lab? 🧪
Im Tech Lab wurde es praktisch: Diese Bühne auf dem d.velop SUMMIT 2025 war der Ort für alle, die Technologie hautnah erleben wollten. Für Tech-Enthusiast:innen und Entwickler:innen bot sie einen tiefen Einblick in die technische Seite von d.velop. Es wurden nicht nur aktuelle Entwicklungen beleuchtet, sondern auch Einblicke in zukünftige Weichenstellungen und die Möglichkeiten, Teil der Entwickler:innen-Community zu werden, gegeben. Passend dazu fand hier auch die KI-Masterclass statt.

Build Your Own Agent: Der digitale Event-App-Assistent
Stell dir vor, du bist auf dem d.velop SUMMIT: Acht Bühnen, zahlreiche Vorträge und spannende Keynotes und alles läuft parallel. Du möchtest wissen „Welche Vorträge handeln von generativer KI?“, „Welche Keynote Speaker sind da?“, „Wo findet das Tech Lab statt?“. Die Agenda zu studieren, interessante Vorträge herauszufiltern und auftauchende Fragen zu beantworten kostet Zeit, die man auf einem Event lieber anders nutzen möchte – und genau hier beginnt der Pain.
Jan und Lars griffen dieses reale Problem auf und machten es zum Herzstück ihrer Masterclass. Ihre Lösung: eine eigene Event-App, der ein digitaler Assistent zugrunde liegt, welcher all diese Fragen beantworten kann, ganz ohne langes Suchen in der Agenda.
Die Idee klingt einfach. Doch wie genau funktioniert so ein Assistent eigentlich? Können wir nicht einfach ein einfaches Sprachmodell wie ChatGPT, Deepseek etc. fragen?
Wir wollen aus unserer Sicht zeigen – sowohl auf konzeptioneller Ebene als auch anhand konkreter Beispiele mit Live-Code, wie man sich eigentlich einen Agenten selber bauen kann und was da im Hintergrund passiert. […] Jetzt machen wir das Ganze natürlich nicht einfach, weil wir es irgendwie können, sondern weil wir damit immer ein konkretes Problem lösen wollen.
Jan Föcking, Senior Software Development Engineer
d.velop AG
Vom Chat zur echten KI-Assistenz – Die nächste Evolutionsstufe von KI
Large Language Models (LLM) entwickeln sich zu Agenten weiter, die verstehen, planen und handeln können. Warum einfache LLMs nicht immer ausreichen und was Agenten zusätzlich brauchen, haben unsere Experten geklärt.
Die Entwicklungsstufen eines autonomen Assistenten
LLM Basics – Warum ein Sprachmodell allein nicht reicht
Jan und Lars starteten mit den Grundlagen: Wie funktioniert eigentlich ein LLM? LLMs sind Sprachmodelle, wie sie zum Beispiel hinter ChatGPT oder Deepseek stecken. Die Basis bilden sogenannte Language Models (LMs) – einfache Sprachmodelle, die Sprache vervollständigen, ähnlich wie die Autovervollständigung auf dem Smartphone.
LLMs funktionieren nach einem ähnlichen Prinzip: Sie schlagen das jeweils nächste Wort vor, basierend auf dem bisherigen Text. Die Ausgabe der ersten Iteration wird dabei direkt an die Eingabe der nächsten Iteration angehängt, so lange, bis eine definierte Stoppbedingung erreicht ist und das gewünschte Ergebnis vorliegt. So entstehen ganze Absätze, Slogans oder Antworten, wie z. B. auf die Eingabe „d.velop SUMMIT“.
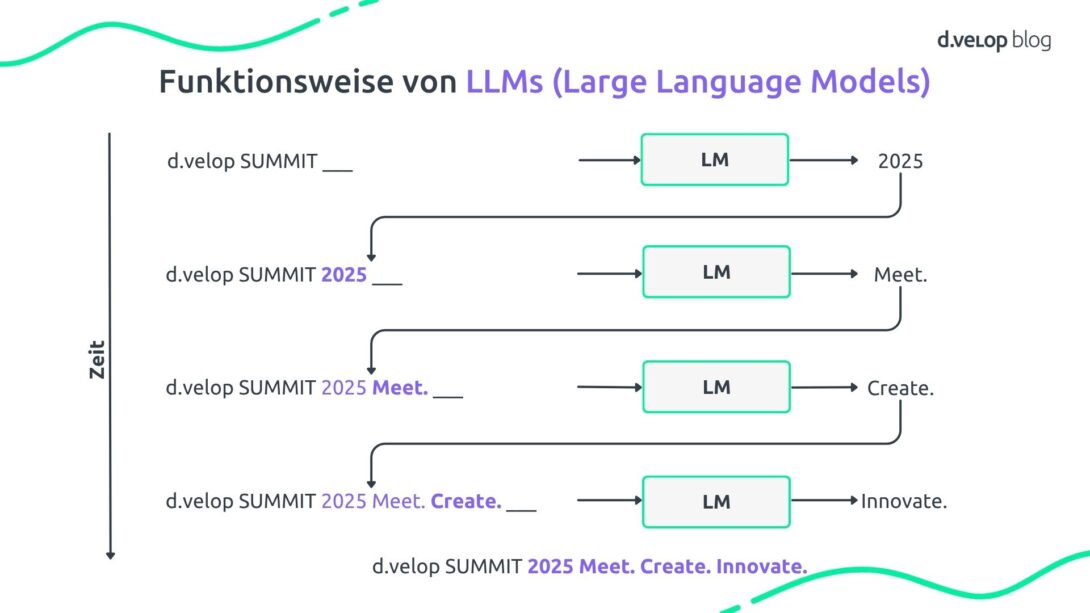
In der Live-Demo zeigten Jan und Lars: Einfache Fragen wie „Wo ist das Areal Böhler?“ beantwortet ein LLM gut. Aber Folgefragen wie „Wie komme ich da mit dem ÖPNV hin?“ scheitern, weil das Modell den vorherigen Kontext nicht kennt.
Zwar kann man den bisherigen Chatverlauf mitgeben, doch das sogenannte Kontextfenster ist begrenzt. Je mehr Text, desto höher der Aufwand und desto größer die Gefahr, dass wichtige Informationen abgeschnitten werden.
Ein weiteres zentrales Problem: LLMs können nur auf Informationen zugreifen, die sie beim Training gesehen haben. Sie können keine aktuellen Daten kennen, etwa zur Event-Agenda des SUMMIT 2025. Stattdessen versuchen sie, Antworten aus bekannten Mustern herzuleiten. Änderungen oder neue Inhalte bleiben außen vor.
Ein eigenes Modell nachzutrainieren, im Fachjargon „Finetuning“, wäre zwar möglich, aber teuer, aufwändig und unflexibel, vor allem, wenn sich Inhalte regelmäßig ändern. Deshalb braucht es eine dynamischere Lösung. Genau hier kommt RAG ins Spiel.
Retrieval-Augmented Generation (RAG) – Relevanz ist, was zählt
RAG steht für „Retrieval-Augmented Generation“, ein Ansatz, bei dem ein LLM zur Laufzeit mit zusätzlichen Informationen versorgt wird, die es selbst nicht kennt. Der Trick: Statt alles ins Modell zu trainieren, geben wir ihm nur die gerade relevanten Inhalte, z.B. aus der Event-Agenda, direkt mit in den Prompt.
Das spart Aufwand, bringt aber neue Herausforderungen mit sich. Auch hier gilt: Das Kontextfenster ist begrenzt. Zu viele Infos machen den Prompt teuer und erhöhen die Gefahr von Halluzinationen. Deshalb braucht es eine Vorverarbeitung, die filtert, was wirklich relevant ist.
Dafür wird Text in sogenannte Embeddings umgewandelt, also Vektoren, die Bedeutung in Zahlen abbilden. Ein Retriever (Filtermechanismus) vergleicht den Vektor der Nutzerfrage mit denen der Inhalte (z. B. Talks) und wählt die ähnlichsten aus. Diese kommen in den Prompt und das LLM kann die Frage beantworten.
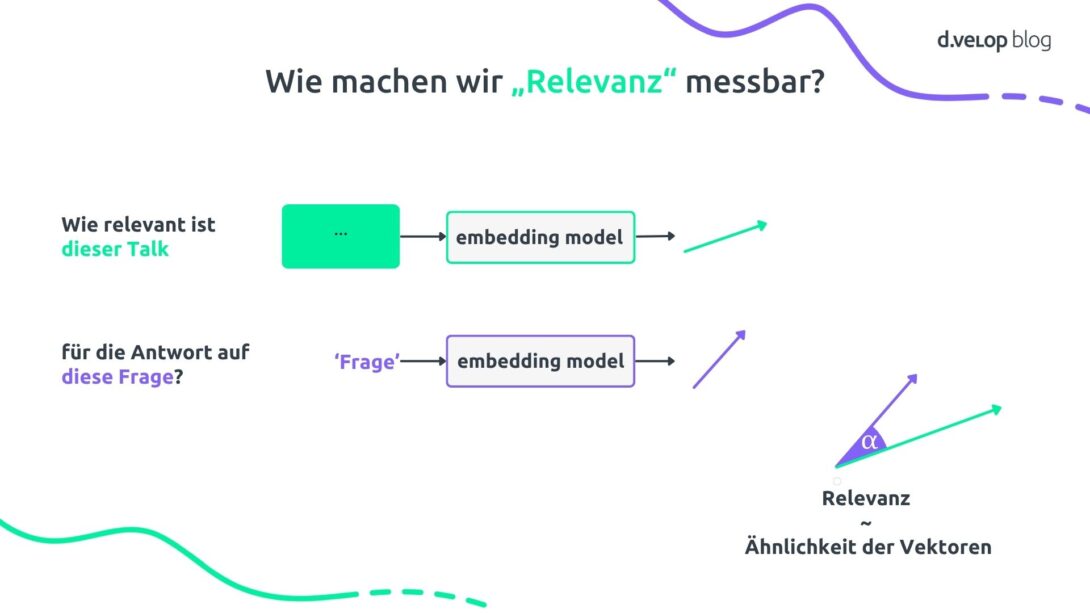
Damit das effizient bleibt, werden die Vektoren im Voraus berechnet und in einer Vektordatenbank gespeichert. So kann der Retriever bei jeder Anfrage schnell darauf zugreifen.
Die beiden erklärten auch, wo RAG an Grenzen stößt. Dies ist bei verneinten oder komplexen Fragen der Fall. Hier reicht reine Ähnlichkeit nicht aus. Dafür braucht es zusätzliche Strukturen wie Knowledge Graphs.
Knowledge Graphs – Von Datenpunkten zu echtem Verständnis
Knowledge Graphs sind eine Technologie, die immer mehr aufkommt. Statt Inhalte nur als Vektoren zu speichern, werden sie in Form von Knoten modelliert. Beispielsweise der d.velop SUMMIT als Knoten sowie Vorträge, Speaker, Bühnen oder Unternehmen als weitere Knoten, die miteinander verknüpft sind. So entsteht ein flexibles, erweiterbares Wissensnetzwerk.
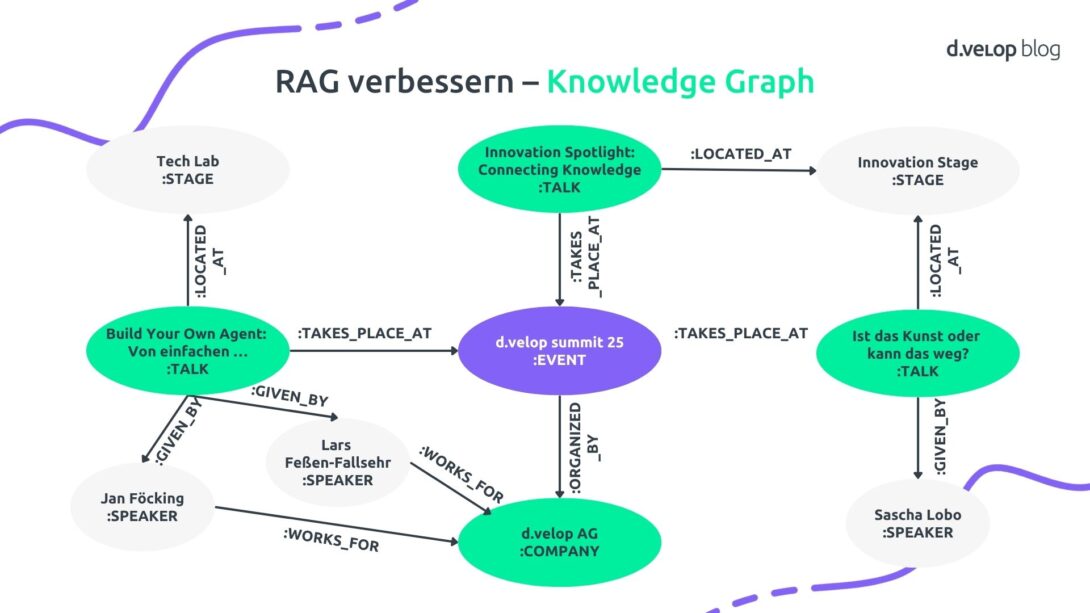
Ein Graph allein ist aber nicht genug, da die Event-App auch darauf zugreifen können muss. LLMs können dabei helfen. Sie sind nicht nur gut im Textgenerieren, sondern auch darin, Codes zu generieren und strukturierte Abfragen zu erstellen. Aus einer natürlichen Frage wie „Welche Vorträge finden auf der Bühne statt, auf der Sascha Lobo spricht?“ kann das Modell eine passende Graph Query erzeugen, die sich von Knoten zu Knoten durch den Graphen hangelt.
Für die Event-App bedeutet das, dass der Indexer (Strukturierer) erweitert wird und zusätzlich zum Vektorindex auch den Graphen aufbaut. Der Retriever führt gezielte Abfragen gegen die Graphdatenbank aus, wandelt die Ergebnisse in Text um und übergibt sie dem LLM zur Beantwortung. So lassen sich deutlich komplexere Fragen beantworten als mit RAG allein.
„Unser Vortrag heißt ja Build Your Own Agent und so richtig agentisch, also dass das System auch wirklich etwas tut und nicht nur Fragen beantwortet, ist bis hierhin noch nicht enthalten.“ Mit diesem Satz leitete Lars über zum nächsten Schritt: der Reasoning Loop, und damit zur eigentlichen Handlungsfähigkeit eines Agenten.
Reasoning Loops & Tools – Agenten in Aktion
Was macht ein System wirklich „agentisch“? Jan und Lars verdeutlichten, dass ein Agent nicht nur Fragen beantwortet, sondern auch eigenständig handeln kann, indem er Tools nutzt, Entscheidungen trifft und Aufgaben Schritt für Schritt abarbeitet, wofür ein Standard-LLM nicht ausreicht.
Hier kommt ein ReAct Agent ins Spiel, bestehend aus einem LLM, einem Memory für den Gesprächsverlauf und Tools, die auf externe Services zugreifen können. Eine Reasoning Loop prüft nach jedem Schritt, ob die Aufgabe gelöst ist. Wenn nicht, wird das nächste Tool aufgerufen. Jeder Schritt wird dokumentiert, der Prompt wächst mit, bis schließlich die Antwort geliefert wird.
Auch in der Event-App wurde dieses Prinzip umgesetzt. Ein Prompt wie „Ich möchte Sascha Lobo sehen, aber nur, wenn Fortuna nicht spielt“ löst eine Kette von Tool-Aufrufen aus (Wikipedia, Spielplan-Check, Kalenderintegration). Erst wenn alle Bedingungen erfüllt sind, wird die Aufgabe abgeschlossen.
Dank eines sogenannten Model Context Protocol (MCP) lassen sich externe Services anbinden, ohne alle Tools selbst zu programmieren. MCP erkennt verfügbare Tools und integriert sie parallel zu eigenen Komponenten.
Von Prompt zu Power: So entsteht aus einem Large Language Model also ein agentenbasiertes System, das nicht nur antwortet, sondern auch aktiv wird.
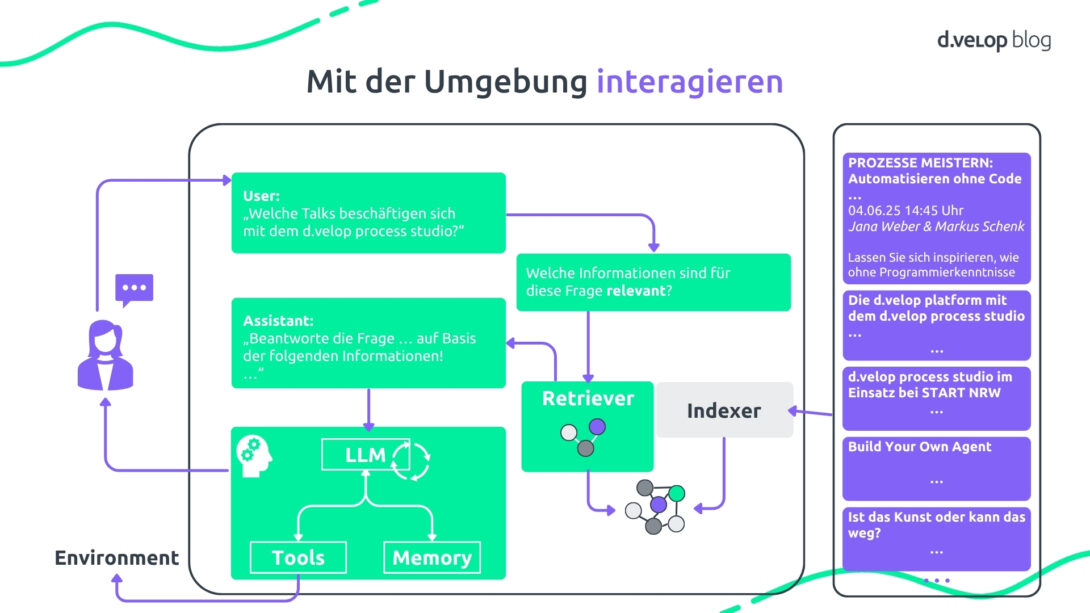
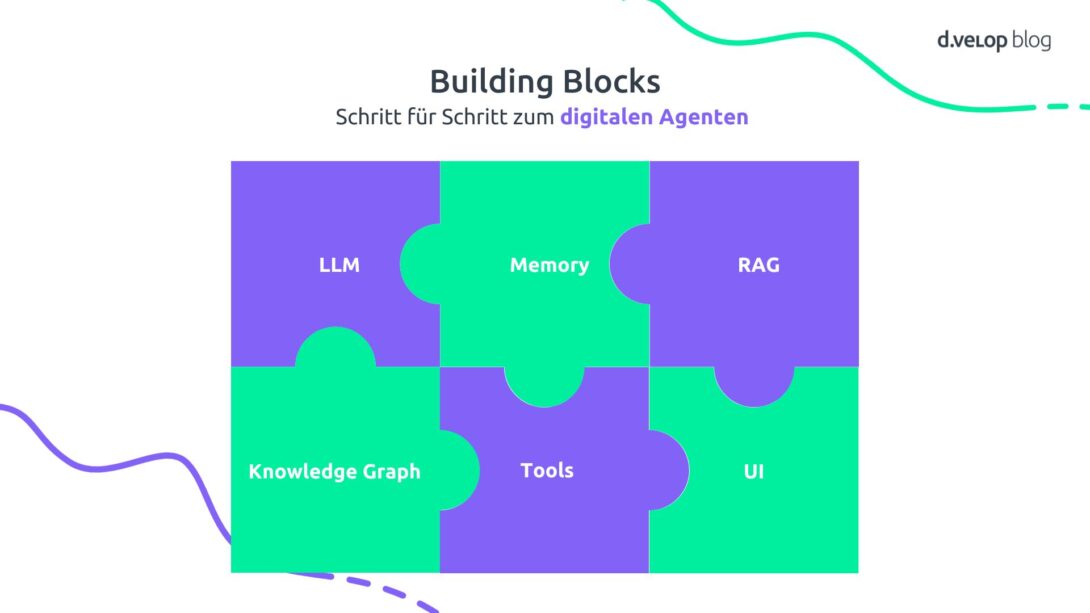
Building Blocks – Schritt für Schritt zum digitalen Agenten am Beispiel der Event-App
- LLM → Beispiel: „Wo ist das Areal Böhler?“ → „… in Düsseldorf …“
Das Large Language Model verarbeitet Nutzerfragen in natürlicher Sprache. Eine Antwort ist nur möglich, wenn die Info im Training enthalten ist.
- Memory: → Beispiel: „Komme ich da mit dem ÖPNV hin?“ → „Ja, das Areal Böhler ist gut mit dem ÖPNV erreichbar.“ Der Agent merkt sich den Kontext vorheriger Eingaben (hier: Areal Böhler) und kann sinnvoll antworten.
- RAG → Beispiel: „Welche Talks beschäftigen sich mit dem d.velop process studio?“ Die Event-Agenda wird nicht in das Modell trainiert, der Retriever sucht relevante Inhalte per Embedding-Vergleich und das LLM antwortet.
- Knowledge Graph → Beispiel: „Welche Vorträge finden auf der Bühne statt, auf der Sascha Lobo spricht?“ → „Auf der Bühne, auf der Sascha Lobo spricht, finden zusätzlich statt …“
RAG reicht für komplexere Fragen nicht aus, das LLM generiert eine Graph Query und die Antwort wird in Text umgewandelt.
- Tools → Beispiel: „Gib mir bitte ein paar Infos zu Sascha Lobo und trage die Keynote im Kalender ein, falls Fortuna Düsseldorf an dem Tag nicht spielt.“ → Wikipedia-Check → Spielplan prüfen → Kalenderintegration. Der Agent wird durch externe Services handlungsfähig.
- UI → Durch die Integration in die Event-App können Nutzer:innen Fragen direkt in der App stellen und der Agent antwortet sofort.
Fazit: Agenten sind die Zukunft – du auch?
Der Deep Dive in dieser Masterclass hat gezeigt: Ein LLM ist nur der Anfang. Erst durch RAG, Knowledge Graphs und Tool-Integration wird daraus ein echter Agent, der auch komplexe Anfragen beantworten kann und damit wirklich „assistiert“. Der Vortrag unserer d.veloper hat verdeutlicht, welches enorme Potenzial Know-How und einige Zeilen Code bereits heute freisetzen können und wie wichtig der richtige Umgang mit der Technologie für unsere digitale Zukunft ist.
Apropos Zukunft: Auch in 2026 findet wieder unser d.velop SUMMIT statt. Denke schon jetzt zukunftweisend und sichere dir dein Ticket, um das neueste KI-Wissen aufzusaugen.
Auch im Dokumentenmanagement kann von künstlicher Intelligenz enorm profitiert werden. Noch mehr KI-Insides und wie sie mithilfe des d.velop pilot im Dokumentenmanagement-System (DMS) integriert werden kann, sind auf unserer Themenseite Künstliche Intelligenz zu finden.
Software Demo zu d.velop documents 💻
Buche mit wenigen Klicks deine individuelle Software-Demo zum d.velop Dokumentenmanagement-System. Erlebe d.velop documents live und stelle direkt deine Fragen an unsere Experten:innen.
Mehr über unsere Speaker
Jan Föcking – Senior Software Development Engineer – Artificial Intelligence | d.velop AG
Jan Föcking ist seit 2016 bei d.velop und hat ein duales Studium Bachelor Wirtschaftsinformatik von 2016 bis 2020 absolviert, was zum Abschluss Bachelor of Arts führte. Anschließend verfolgte er einen berufsbegleitenden Masterstudiengang in Wirtschaftsinformatik von 2020 bis 2023, wodurch er den Abschluss M. Sc. erlangte. Bis 2023 arbeitete er als Software-Engineer im Bereich Dokumenten-Import und seitdem Jahr ist er als Software-Engineer für künstliche Intelligenz tätig. Seine Schwerpunkte liegen dabei auf generativer KI, Retrieval-Augmented-Generation, Large Language Models und Cloud Computing.
Lars Feßen-Fallsehr – Senior Software Development Engineer – Artificial Intelligence | d.velop AG
Lars Feßen-Fallsehr ist seit 2017 bei d.velop tätig und hat zuvor ein duales Studium mit dem Abschluss Bachelor of Science in Informatik absolviert. Seinen berufsbegleitenden Master of Science in Data Science hat er im Jahr 2020 erfolgreich abgeschlossen. Von Anfang 2017 bis 2019 arbeitete Lars als Software-Engineer im Bereich Aufgaben- und Prozess-Management und seit 2019 ist er als Software-Engineer für künstliche Intelligenz bei d.velop tätig. Sein Fokus liegt dabei auf generativer KI, Retrieval-Augmented-Generation, Large Language Models und Cloud Computing.