
Tagtäglich erreichen Unternehmen hunderte, in vielen Fällen tausende von Dokumenten auf unterschiedlichsten Wegen und in verschiedensten Formaten. Das fängt bei der klassischen Briefpost an und hört bei E-Mails mit einer Vielzahl von möglichen Anhängen noch lange nicht auf. Diese Datenflut zu bändigen, ja mehr noch, die enthaltenen Informationen aufzubereiten und für das Unternehmen nutzbar zu machen, stellt eine der wesentlichen Herausforderungen der digitalisierten Geschäftswelt dar.
Flaschenhals manuelle Ablage
Die rein manuelle Ablage von Dokumenten stellt sich dabei nur allzu häufig als Flaschenhals heraus – sie ist gleichermaßen mühsam, zeitraubend und repetitiv. Moderne Ansätze des Machine Learnings (oder weiter gefasst: Der künstlichen Intelligenz) versprechen Linderung. Mit ihrer Hilfe lassen sich viele Arbeitsschritte automatisieren beziehungsweise mit automatisch generierten Empfehlungen in einem Dokumentenmanagement-System unterstützen. Auf diese Weise spart man Zeit, reduziert Kosten und vermeidet stoische, demotivierende Tätigkeiten.
Automatische Kategorisierung mittels neuronaler Netze
Im Portfolio der d.velop Gruppe haben derartige Verfahren bereits seit mehr als 15 Jahren einen festen Platz. Neuere Entwicklungen, die den weitreichenden Einsatz mehrschichtiger neuronaler Netze („Deep Learning“) ermöglichen, helfen uns dabei, diese Funktionalität kontinuierlich zu verbessern. In diesem Artikel geben wir eine konkrete Antwort auf eine Frage, die Mario Dönnebrink unlängst formuliert hat: „Wie wäre es jetzt, wenn Sie zukünftig neu hinzukommende Informationen und Dokumente gar nicht mehr manuell in Ihre Aktenstrukturen ablegen müssten, sondern wenn das ECM-System dies eigenständig lernt?“
Denn genau das tun wir heute: Wir nutzen tiefe neuronale Netze (DNN) für die Kategorisierung eingehender Dokumente. Eine Analyse des Dokumenteninhalts liefert vollautomatisch die Zuordnung des Dokuments zu einer Kategorie, unter der es abgelegt werden kann. Eine eingehende Rechnung wird beispielsweise als solche erkannt. Diese kann nun nicht nur am richtigen Ort abgelegt werden, sondern es können auch nachgelagerte Prozesse – im Beispiel die Rechnungsprüfung – automatisch angestoßen werden. Ein manuelles Eingreifen ist möglich aber nicht nötig. Im Folgenden beschreiben wir anschaulich, wie die Technik hinter diesem Feature funktioniert.
Word Embeddings – Rechnen mit Dokumenten
Ausgangspunkt ist der Fließtext des eingehenden Dokuments. Nach einer Aufbereitung werden mittels eines DNN sogenannte „Word Embeddings“ [1] für den Text berechnet. Dabei handelt es sich mathematisch um mehrdimensionale Vektoren, die bildlich gesprochen das Rechnen mit Worten bzw. mit deren Bedeutung ermöglichen. Gute Embeddings zeichnen dadurch aus, dass sie ähnlichen Worten eine ähnliche mathematische Beschreibung zuordnen. Das Wort „Mahnung“ landet z.B. in der Nähe von „Zahlungserinnerung“. Auf dieser Basis lassen sich Ähnlichkeiten zwischen Worten und damit auch zwischen Dokumenten berechnen (vgl. Abb. 1). Füttert man das Verfahren nun mit Beispieldokumenten, für die man die jeweilige Kategorie kennt, lernt es anschaulich „Parzellen“ für die einzelnen Kategorien. Bittet man das trainierte System nun, ein bisher unbekanntes Dokument zu klassifizieren, so errechnet es mittels Embeddings die „Parzelle“ und darüber die zugehörige Kategorie, in die das Dokument eingeordnet werden soll. Et voilà!
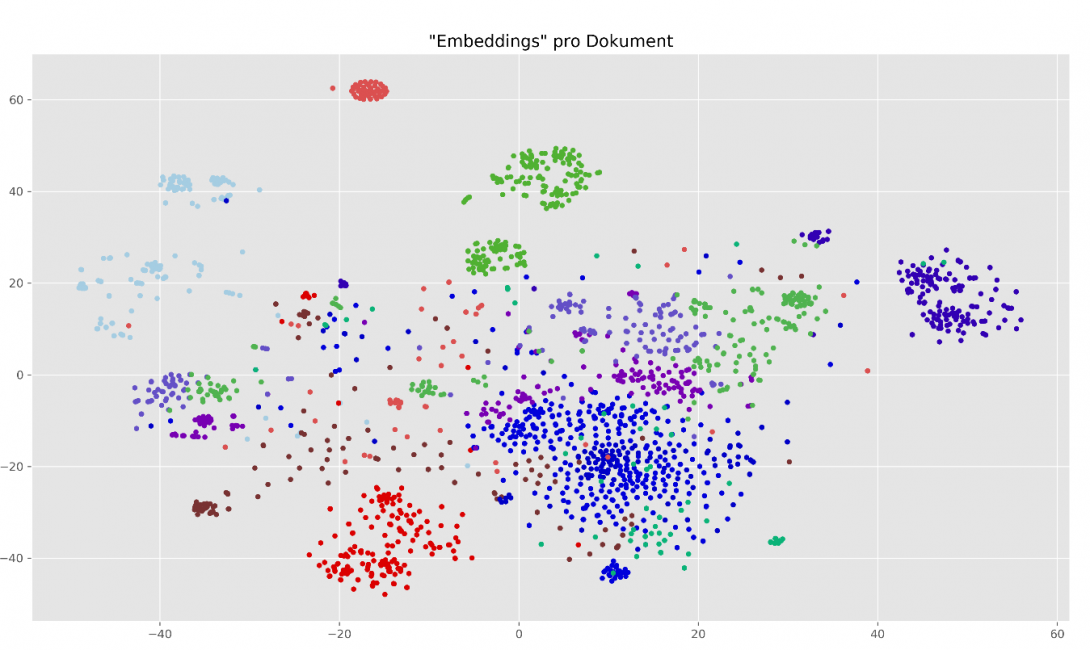
Abb. 1: Der Rechner „sieht“ Dokumente auf Basis ihrer Embeddings. Jeder Punkt im Diagramm repräsentiert ein Dokument. Die Farbe kodiert dessen Kategorie. Die gewählten Embeddings bilden Dokumente einer Kategorie auf nahe beieinander liegende Punkte im Diagramm ab. Dies verdeutlicht die „Parzellen“, die eine Kategorisierung neuer Dokumente ermöglichen.
Da das Verfahren ausschließlich den Rohtext eines Dokuments als Eingabe verlangt, eignet es sich zur Klassifizierung einer Vielzahl verschiedener Eingangsformate. Unabhängig davon, ob die Dokumente in Form von Scans, PDFs oder Emails eingehen. Sobald der Dokumentinhalt – der Text – einmal vorliegt, kann das Dokument automatisch abgelegt werden. Darüber hinaus ist das System unabhängig von starren Regelkorsetten. Was das heißt? Es benötigt keine Musterbriefköpfe oder fest vorgegebene Schlüsselworte. Somit klassifiziert es auch Dokumente bisher unbekannter Absender zuverlässig.
Aus vorhandenen Daten lernen
Experimente zeigen, dass bereits 500 Beispiele pro Dokumentenkategorie ausreichen, um die Kategorie bisher nicht gesehener Dokumente in mehr als 90% der Fälle richtig zu bestimmen. Und hier kommen Sie ins Spiel: Als Nutzer eines DMS Systems besitzen Sie schon heute einen großen Fundus an Dokumenten, den Sie und Ihre Mitarbeiter über Jahre hinweg akribisch in Ihre virtuellen Aktenstrukturen eingepflegt haben. Ihre Daten sind nun eine wesentliche Zutat auf dem Weg zur automatischen Klassifizierung. Unser System lernt aus diesen Daten, wie Sie Ihre Dokumente sortieren. Sind die Daten einmal vorhanden, dauert ein Trainingsvorgang nur wenige Minuten. Die Klassifizierung eines einzelnen Dokuments beansprucht anschließend nur einige hundert Millisekunden – für jedes neu eingehende Dokument, reproduzierbar und vollautomatisch. Und sollte der Algorithmus doch einmal daneben liegen, haben sie jederzeit die Möglichkeit, das Ergebnis zu korrigieren – das Verfahren bedankt sich, indem es aus dem Fehler lernt und versucht, diesen in Zukunft zu vermeiden.
Unternehmen können vom Input-Management ihres ECM-Systems profitieren
Laut Bitkom-Studie nutzen überraschenderweise nur 26.3% der befragten Unternehmen ihr zentrales ECM-System für das Input-Management [2]. Die automatisierte Kategorisierung von Dokumenten leistet einen wichtigen Beitrag, diese Quote zu verbessern. Im Rahmen der Ablage werden Klassifizierungsergebnisse zur Vorauswahl der Ablagekategorie genutzt. Diese ersparen unnötige, manuelle Eingaben, können aber bei Bedarf vom Benutzer korrigiert werden. Im Anschluss erlaubt die Klassifizierung das zielgerichtete Starten nachgelagerter Prozesse. Zu guter Letzt erleichtert die konsistente, automatische Vergabe von Kategorien das Wiederfinden von Dokumenten. Inhalte werden so prozessübergreifend vernetzt. In Summe stellt die KI-gestützte Klassifizierung somit einen pragmatischen und dennoch wesentlichen Schritt im Hinblick auf eine ganzheitlich integrierte Betrachtung Ihres Dokumentenbestandes dar.
Digitales Dokumentenmanagement einfach erklärt.